ollvm小记
;)
其实这学期初就接触到零碎的东西,但是五月初才完全实践了一下,记录一下/(^o^)/~
ollvm与llvm
ollvm是 llvm编译器框架的一种扩展,它用于实现 代码混淆,即故意使程序的源代码或二进制代码变得更加难以理解、逆向工程或破解。
ollvm的混淆是通过修改 llvm IR 实现的,整个项目包含了三个相对独立的LLVM pass,每个pass实现了一种混淆方式。
ollvm其衍生技术仍然是当前移动应用安全加固(包括iOS和Android)中的重要工具之一,尤其是在代码混淆和反逆向工程领域。
当然啦,技术在不断的更新先做这方面的了解。

这里有几个概念记一下:
IR
IR 介于高级语言(如C/C++)和机器码之间,抽象了硬件细节,使编译器能跨平台优化。
1 | 源代码 → IR → 目标机器码(x86/ARM等) |
LLVM IR有两种文件格式.ll和.bc,.ll 文件和 .bc 文件都是 LLVM 中间表示的不同表示形式。
.ll 文件是文本形式的可读表示,方便分析和调试
.bc 文件是二进制形式的紧凑表示
PS:之前遇到过将.bc文件转化成exe文件的,记一下,最后exe文件在含clang的bin文件里
1 | 路径 |
pass
LLVM的pass框架是LLVM系统的一个很重要的部分。LLVM的优化和转换工作就是由多个pass来一起完成得。
每个Pass负责一项具体任务,有优化、混淆等等
怎么理解呢
感觉就像流水线上的工人每个人有自己干的活
clang
LLVM与Clang是C/C++编译器套件。对于整个LLVM的框架来说,包含了Clang,因为Clang是LLVM的框架的一部分,是它的一个C/C++的前端。功能的角度来说,LLVM可以认为是一个编译器的后端,而clang是一个编译器的前端。
一个编译器前端想要程序最终变成可执行文件,是缺少不了对编译器后端的介绍的。
环境配置
Ubuntu 24.04(内存4G,硬盘100G,磁盘空间放大一点可以省去硬盘扩容的操作,这个还蛮重要的因为我的是新的pwn环境捏,所以躲掉了这边)
换成国内源
以下命令之后删除原有内容,替换为阿里源(注意Ubuntu 24.04 Noble Numbat 的源)
1 | cp /etc/apt/sources.list /etc/apt/sources.list.bak |
编译工具:cmake , gcc , g++
cmake的版本,gcc、g++都要为8.x的不然无法编译

可以先下载一下8版本的,然后调整一下优先级
1 | sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-8 80 |
啊哈哈
在llvm编译的时候常常会遇到要扩容的问题,如果编译有问题的话多数是这
先硬盘扩容vmware:ubuntu虚拟机如何扩容?_vmware ubuntu scsi硬盘扩容-CSDN博客
再swap分区扩容[如何在Ubuntu上增加swap交换空间_Linux教程_Linux公社-Linux系统门户网站](https://www.linuxidc.com/Linux/2019-07/159580.htm#:~:text=如何在Ubuntu上增加swap交换空间 1 第2步:检查分区上的可用空间 2 第3步:在Ubuntu中创建swap文件 3,第4步:在Ubuntu中启用swap文件 4 第5步:在Ubuntu中永久挂载交换文件 5 第6步:调整Ubuntu中的交换设置 6 第7步:删除Ubuntu中的交换文件)
ollvm的搭建
1 | git clone -b llvm-4.0 --depth=1 https://github.com/obfuscator-llvm/obfuscator.git |
然后修改ollvm源码,进入 ollvm目录,我的路径长下面这样,这里要注意一下路径才能找到自己的OrcRemoteTargetClient.h文件 ,在这一步忙了好久气死我了
~/obfuscator//include/llvm/ExecutionEngine/Orc/OrcRemoteTargetClient.h
定位到第690行 把char 改成 uint_8t
在 obfuscator的同级目录下创造一个build目录
1 | cd ~ # 确保回到用户根目录,因为我这边将其装在了根目录 |
make install会将软件安装到当前用户的目录下
sudo make install会将软件安装到系统的全局目录下,以便所有用户都可以使用。
根据自己的要求选择
好啦,至此我们的环境就配好了,接下来实践一下
ollvm混淆
在生成IR后、优化前插入混淆Pass
首先混淆有两种方法
一种是配置ndk环境混淆,另一种是直接将clang作为程序进行混淆。
这里我用的是第二种方法因为比较方便一点
如果想看第一种的,学习的时候感觉这个文章写的很详细,先记一下怕以后会用到捏
OLLVM混淆环境搭建与去平坦化 - 吾爱破解 - 52pojie.cn
在用clang的时候需要跳到build/bin文件下面再操作
其次准备一个测试代码,注意选择那种有包含多个简单运算,可以展示混淆结果的。
最好还能通过命令行参数控制不同的执行路径。
我用的是这个
1 | #include <stdio.h> |
首先没有混淆前用普通的gcc编译一下长这样,好亲切的程序啊
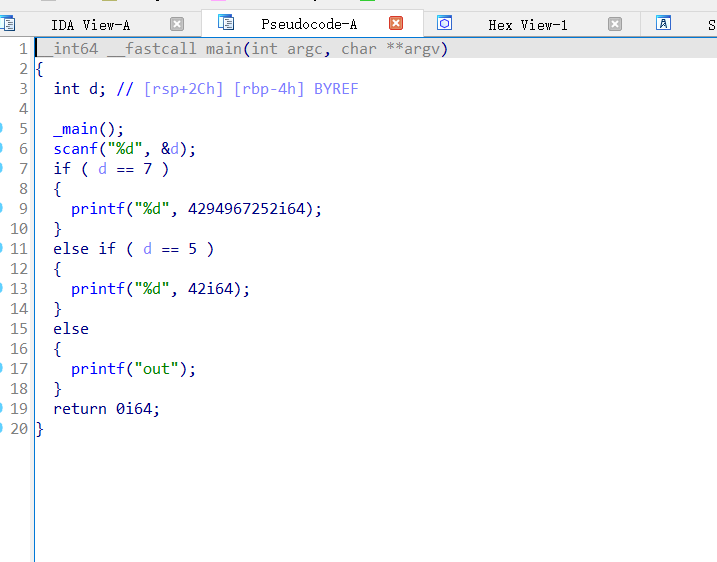
再贴一下它的流程图,十分清晰哈
控制流扁平化
将程序原有的结构化控制流转换为平坦的状态机形式
其实就是将真实块处理成while和switch结构,变得很丑
1 | ./clang -mllvm -fla '/root/Desktop/main.c' -o fla1 |
混淆之后再打开变成了这样子
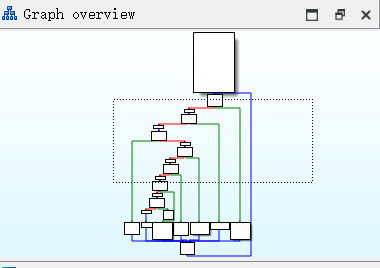
但是仍然感觉没有之前写的题恶心,这是因为其实这个控制流下面还有其它编译器选项可以选
- -fla :先扁平化控制流
- -split :拆分基本块 基本块被拆成多个小块
- -split_num=3:拆分次数 默认为1,这边是3,说明一个基本块被拆分了4次
1 | ./clang -mllvm -fla -mllvm -split -mllvm -split_num=3 '/root/Desktop/main.c' -o fla2 |
用完之后果然^-^恶心多了
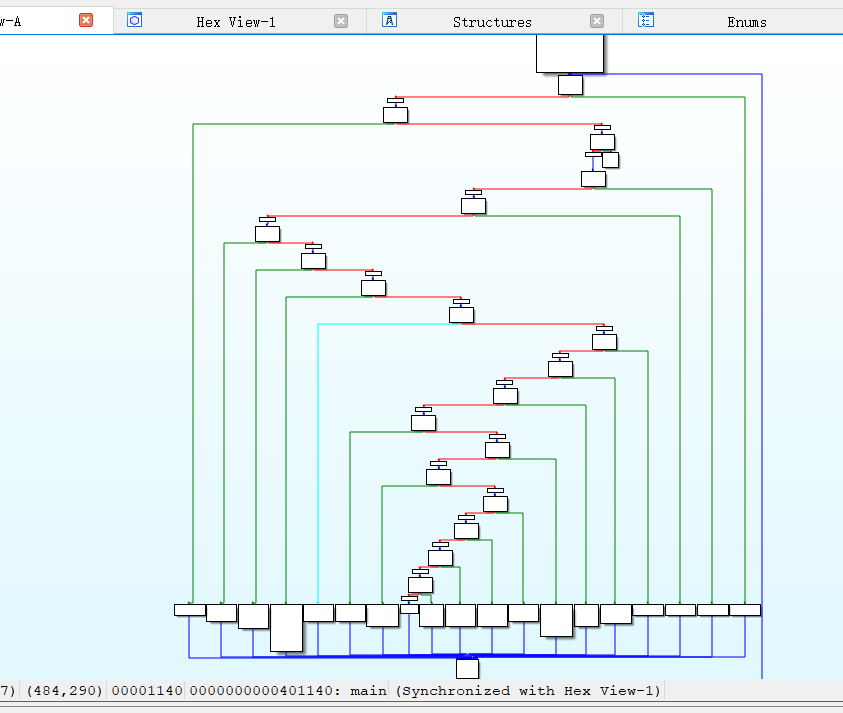
用D810解一下混淆两次也不一样,第一次解混淆的基本和原来的一模一样,第二次先贴个图,还是有好多没有用的东西,但其实大都是没用的赋值,而且动调也不太方便TvT好像得看汇编呢

但是这里用angr解混淆的话就特别清爽,如下。哈哈看来还是要选择合适的解法捏
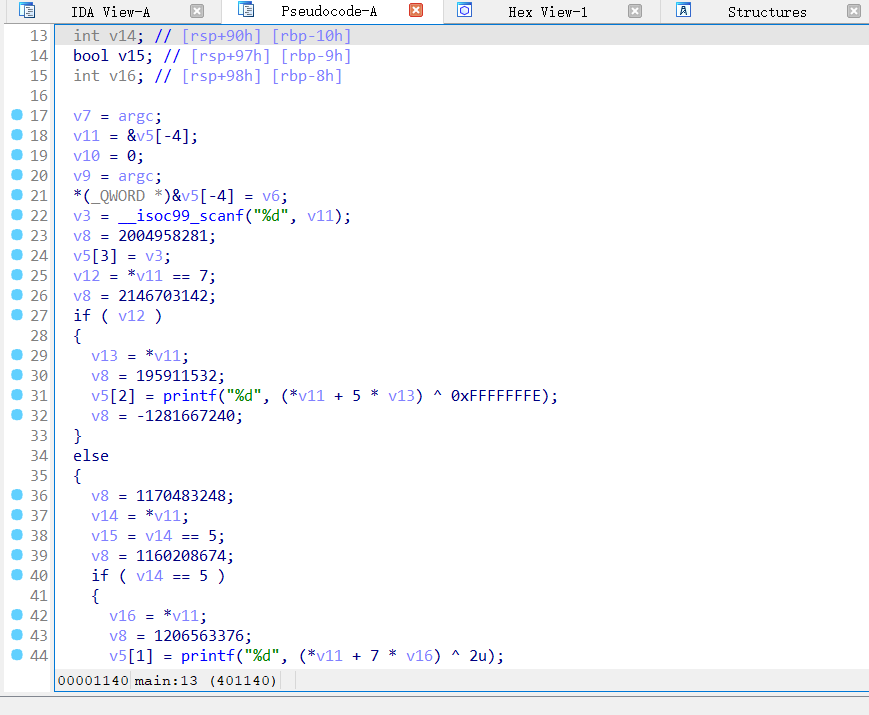
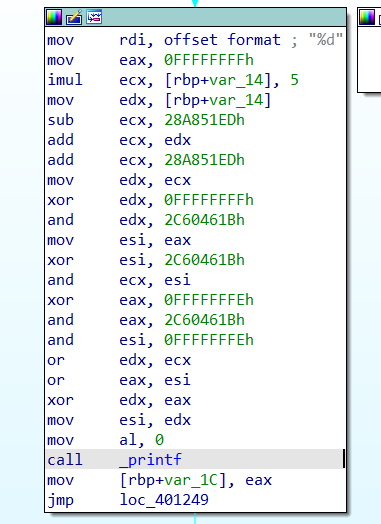
指令替换
将简单的指令或操作替换为功能相同但更复杂的等效指令序列
1 | ./clang -mllvm -sub '/root/Desktop/T v T/main.c' -o sub1 |
其实看反汇编的地方看不出什么明堂几乎没有变,在流程图里就能清晰的看到啦
主要是做了一些加减异或上的东西
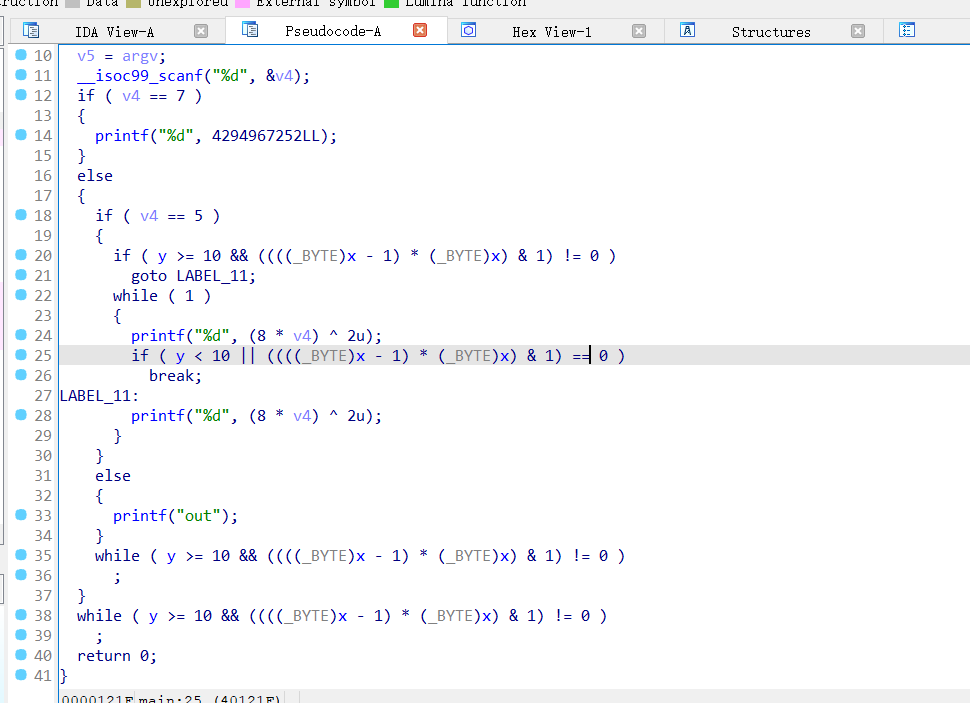
虚假控制流程
在代码中插入永远不会执行的条件分支和代码块,也就是垃圾代码
1 | ./clang -mllvm -bcf '/root/Desktop/T v T/main.c' -o buf1 |
混淆过后果然和源代码之间有点差别,中间很多没有用的
但是用D810去掉之后与原来代码一样
ollvm去混淆的方法
关于控制流扁平化的话:
1.ida里有D810的插件
2.基于angr的脚本deflat.py去除
主要看情况吧想脚本的话有的时候很多重要的函数都被混淆了,一个个找地址很麻烦的,不如用d810,但是呢如果有些地方被魔改了,还是要用脚本修改修改来解混淆。
虚假控制流
D810中内置了很多的不透明谓词表达式,它的匹配器也是非常的厉害完全可以做到去除虚假控制流
在D810打开之后,选择default_unflattening_switch_case.json,之后点击start , 即可做到对不透明谓词的去除并还原控制流。
如果发现有一些恒定值的不透明谓词表达式 D810 没有识别到无法去除的话,我们也可以手动添加规则让 D810 进行匹配来消除啊哈哈
指令替换
直接D810跑,神器
总结
其实这里可以学的东西还有很多,包括试着修改一下它的原本pass来混淆(等我变强了再来挑战),还有分析函数块来去混淆,自己还有很多地方不足,等自己努力学懂了再整理一下思路吧。
主要还是自己第一次了解到IR这种东西,而且后面还碰到好多稀奇古怪的文件,这让我明白了其实后面还有很多东西。
“
re题型的输入可能是什么
答:从源文件到二进制文件编译过程中所有可能的文件,如源文件.c、任何形式的ir、汇编.s、目标文件.obj、可执行文件elf等等。
”
(⊙o⊙)…
这是我在一篇文章里看到的很有想法的话
希望自己后面的小朋友学习能抱着充实自己的形态不断学下去O(∩_∩)O~~




